

Beyond RAG: Introducing Papr Context Intelligence
Turning memory into reasoning, insights, and analytics for AI agents

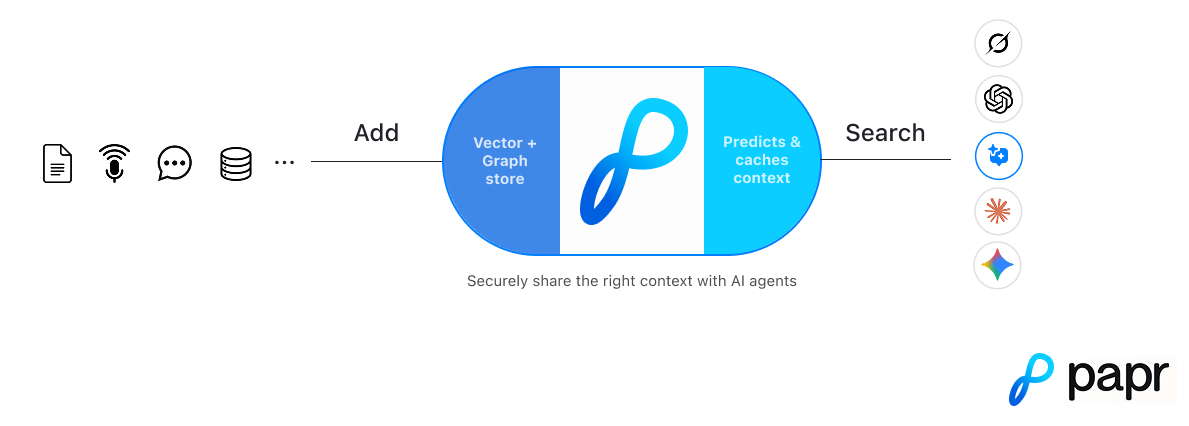
A few months ago, we launched Papr —the predictive memory layer that helps AI agents remember. Instead of just storing memories, we predict and trace the connections between them. This context arrives at your agent in real-time, exactly when it’s needed.
Today, we’re building on that foundation. We’re introducing Papr Context Intelligence: the ability for agents to not only remember context, but to reason over it, generate insights, and understand what changed and why. Try it for free.
Most AI agents today are built on fragmented systems. Vector databases handle semantic search. Knowledge graphs store structured relationships. Conversations live somewhere else. External data is stitched in through RAG (retrieval augmented generation) pipelines. Each system works in isolation—but real world questions don’t.
As a result, agents retrieve pieces of information without understanding how they fit together, what changed most recently, or why something is happening. Managing this stack is complex, expensive, and brittle—and even then, agents still miss the full picture.
Papr was built to fix this.
The Problem with Fragmented Memory
Teams building AI agents consistently run into two fundamental problems.
1. Conversational search is inaccurate
Vector search is fast, but it is goal- and state-blind. It retrieves semantically similar content, not information that reflects intent, causality, or what has changed most recently. In practice, conversational context is split across systems: prior conversations may live in a memory store, while documents, code, timelines, and operational data live in separate RAG systems and are retrieved independently.
When a user asks “What’s blocking launch?” or “What’s the current status?”, the relevant information often spans conversations, documents, events, and plans across different teams and tools. Semantically, these pieces are far apart in vector space—they use different vocabulary, belong to different domains, and describe different types of work. That separation is expected from a semantic perspective, but from a human perspective they are tightly connected by a shared goal, a shared state, and a timeline of updates.
Traditional vector search returns fragments. You might retrieve an implementation update or an outdated plan, but miss the dependency or approval that is actually blocking progress. The result is incomplete context, stale answers, and agents that understand text but not what’s actually going on.
2. Agents can retrieve context, but can’t generate insights
Even when retrieval improves, a deeper problem remains. Retrieval answers what is relevant; insight requires answering what changed, why it happened, and what it impacts. Vector databases aren’t designed for this—they return similar content, not structured explanations or reasoning.
Knowledge graphs are better suited for insights. They can represent relationships, dependencies, timelines, and metrics. But they come with tradeoffs: ingesting unstructured data requires complex pipelines, multi-hop queries are too slow for real-time conversational use, and most graph systems are optimized for static dashboards—not dynamic assistants asking new questions on the fly.
As soon as teams need both conversational search and structured insights, the architecture fractures. Vector databases, knowledge graphs, conversation stores, ETL pipelines, and multiple APIs all have to be stitched together and kept in sync. When one system lags, answers become stale or inconsistent.
A predictive memory and context intelligence layer for AI agents
Papr gives AI agents the ability to understand context, reason over relationships, and generate insights—without stitching together multiple systems. With addMemory API call, conversations, documents, events, and structured data are organized into a unified memory that stays consistent and improves over time.
1. Understand relationships and context across conversations and time
Papr allows agents to retrieve the right information using natural language, even when the same concept is expressed differently across sources. Beyond retrieval, Papr enables agents to understand how information connects across people, entities, events, decisions, timelines, and dependencies.
This makes it possible for agents to answer questions that require understanding what depends on what, what changed, and what is currently blocking progress. Because conversational history is part of the same memory system, agents can reason across past discussions and current data, explain situations in terms of cause and impact, and maintain continuity over time instead of returning disconnected snippets.
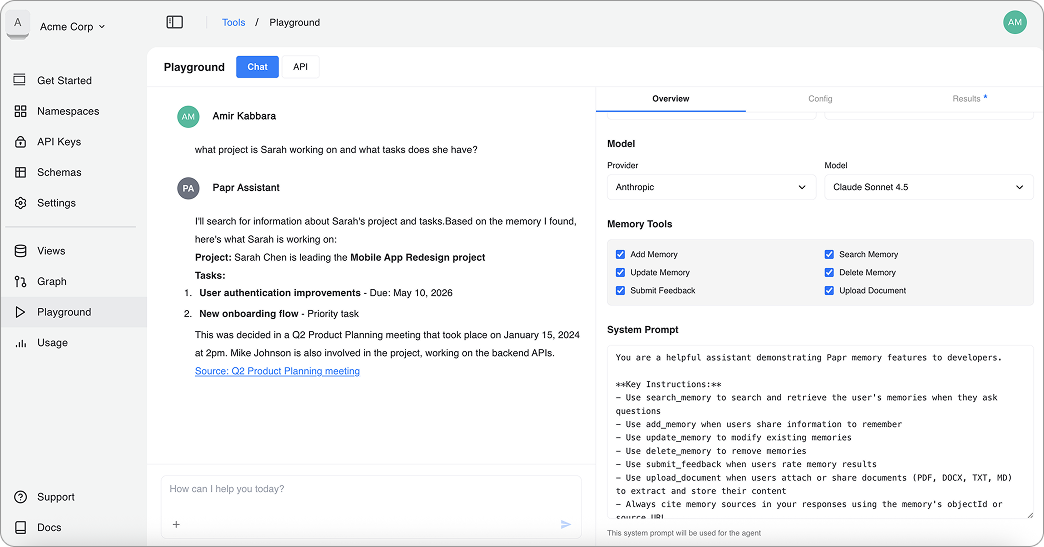
2. Generate insights and analytics via natural language or GraphQL
Retrieval alone isn’t enough—agents also need to explain what’s happening and why. Papr makes this possible by storing memory in a structured way that supports both conversational and analytical queries.
For conversational assistants, agents use natural language to surface insights dynamically, combining semantic retrieval with relationship reasoning to answer questions like what changed, why it happened, and what it impacts. For dashboards and internal tools, developers use GraphQL to query the same memory in a structured way, enabling analytics that reason over entities, relationships, timelines, and patterns—not just raw metrics. The same underlying memory powers both experiences, without duplicating data or logic.
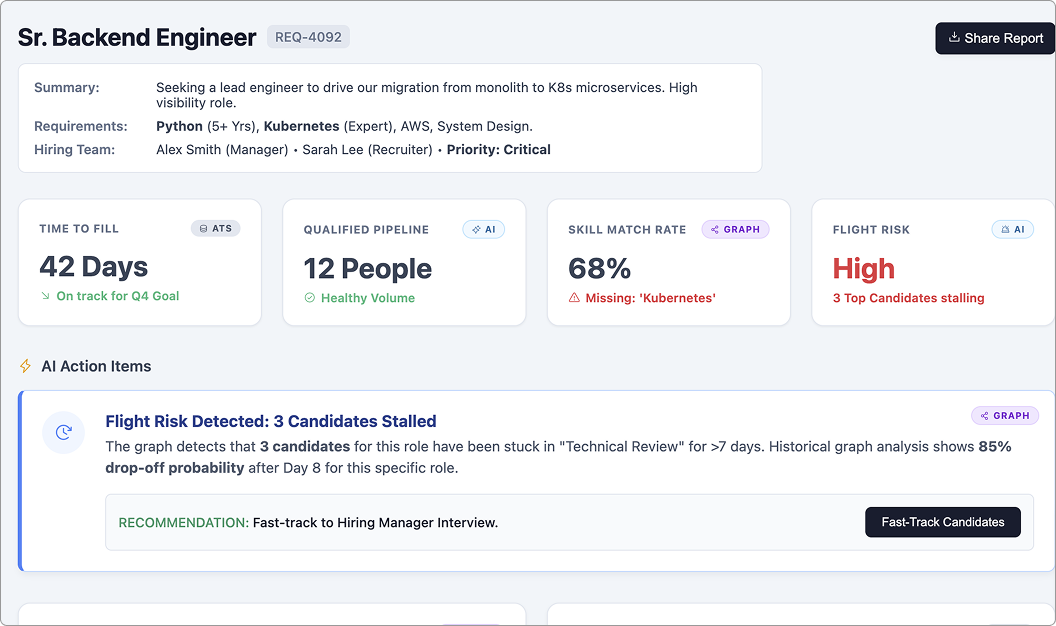
3. Predict what matters by learning from real usage
Papr learns from how information is actually used. When certain pieces of context are frequently accessed together or in sequence, those connections are strengthened automatically. This captures implicit relationships that don’t exist in schemas or documents and allows agents to anticipate what context will be needed next. Over time, this predictive memory reduces latency, improves relevance, and helps agents surface the right follow-up information without manual rules, tuning, or retraining.
Getting Started
You can start using Papr in minutes. Define a schema if you want structured relationships, or skip it and let Papr learn from usage. Add memory with a single API call. Query everything together using natural language or GraphQL.
If you’re building AI agents that need more than retrieval—agents that need to understand state, reason over change, and stay consistent over time—Papr is built for you.
👉 Get started at platform.papr.ai. Sign up for free or use the open source edition
Really strong framing on the goal-and-state blindness issue with vector search. I've run into this repeatedly when building agentic workflows, where the semantic similarity gets you 70% there but totally misses recency, causality, or state transitions. The multipl-system fragmentation is brutal too, especially when youre trying to keep conversation memory, docs, and event logs in sync. Curious how the predictive learning handles edge cases where usage patterns dont reflect actual importance, like rarely accessed but critical compliance docs?