

The Trillion-Dollar Architecture Shift: Why AI Agents Need Context Graphs, Not Just Vectors
The case for context graphs + memory policies, and a hands-on guide to building AI agents that actually reason

Last week we shipped memory policies and graph constraints in Papr’s Python SDK (v2.21.0) and TypeScript SDK. It’s the kind of release that doesn’t have a flashy demo video, but quietly changes how production agents work. I’ve been thinking about why this matters — not just for us, but for anyone building agents that need to do more than parrot back similar text.
Here’s the uncomfortable truth most of us in the AI infrastructure space don’t talk about enough: vector embeddings are necessary for AI memory. They are not sufficient for AI agents.
The problem nobody wants to admit
Embeddings are brilliant at one thing: finding text that sounds like other text. You ask “What’s the project deadline?” and semantic search finds the memory where someone said “We moved the deadline to March 15th.” Beautiful. Ship it.
But then your agent gets a real question. Not a lookup — a reasoning question.
“What happened before this decision?” “Who approved this exception — and did they have the authority to?” “Is this entity allowed to exist, or does it need to link to a controlled vocabulary?” “What’s the relationship path connecting account risk, incident history, and this renewal conversation?”
Similarity can’t answer these. And this isn’t a retrieval quality problem — it’s a structural one. You’re asking a system that only understands “sounds like” to understand “connects to” and “is governed by.” It’s like asking a search engine to be a database.
I see this every week in conversations with teams building agents. The demo works. The pilot works. Then they hit production and suddenly the agent is hallucinating categories, inventing entities that shouldn’t exist, and returning fragments instead of understanding. More data makes it worse, not better. We’ve written about this before as context rot— and it’s the core architectural problem of the current generation of AI memory systems.
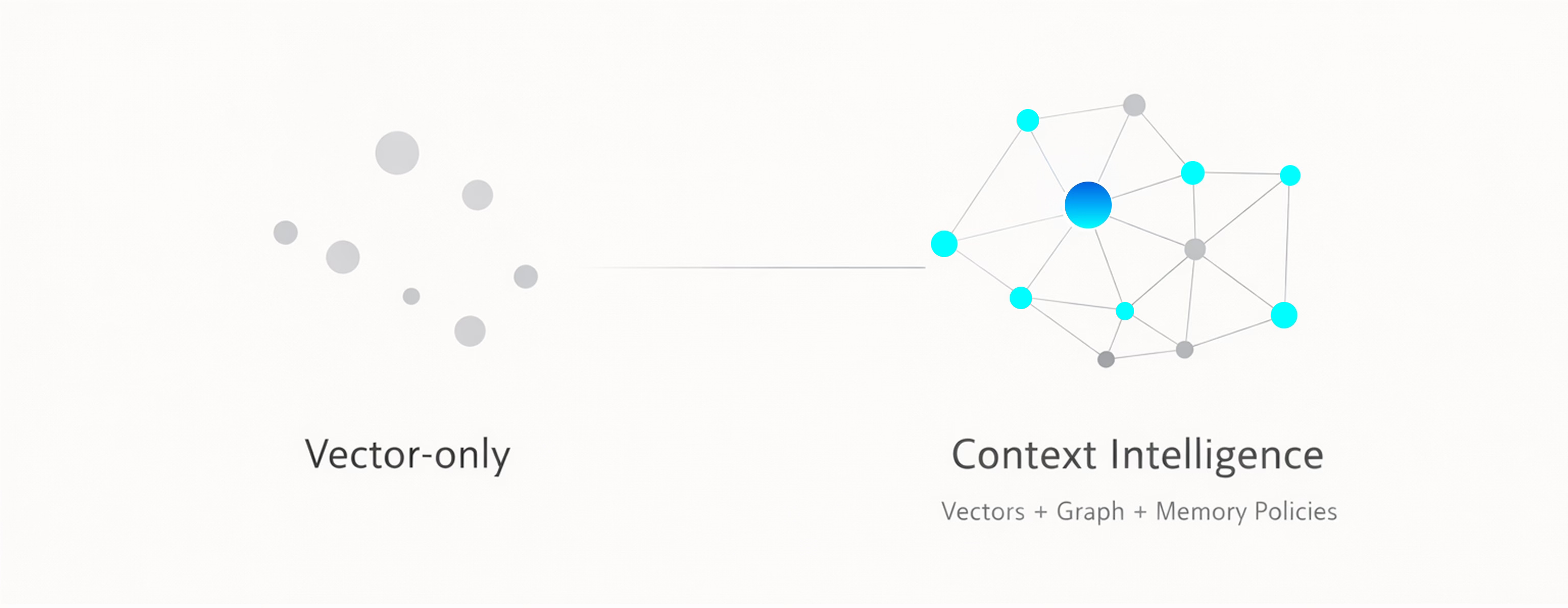
Here’s what this looks like in practice. On the left: vector-only memory. Dots floating in embedding space. Five duplicates of “pricing inquiry” with no dedup, no connection between Sarah → Acme → Deal → Risk. On the right: a context graph with policies. One canonical entity per concept, full traversal paths, every node traceable.

The visual tells the whole story. Vectors give you clusters of similar text. Graphs give you a web of connected meaning. One is a filing cabinet. The other is a brain.
Why graphs change the game
A context graph is where entities, events, and rationale are connected across time. It’s not just a knowledge graph in the traditional sense — it’s a decision trace. As Jaya Gupta and Ashu Garg at Foundation Capital describe it, the next systems of record won’t just store objects. They’ll store the reasoning behind decisions, the exceptions that were made, and the lineage of how conclusions were reached.
This is exactly what we’ve been building at Papr. When you define a schema and add memories, the engine doesn’t just embed text — it extracts entities, traces relationships, and builds a queryable graph that your agent can traverse with natural language or GraphQL.
But here’s what we learned shipping this to production teams: graph structure alone is also not enough. You also need execution-time controls over how entities get created, which rules apply under what conditions, and what safety constraints govern memory use.
This is exactly what we’ve been building at Papr. When you define a schema and add memories, the engine doesn’t just embed text — it extracts entities, traces relationships, and builds a queryable graph that your agent can traverse with natural language or GraphQL.
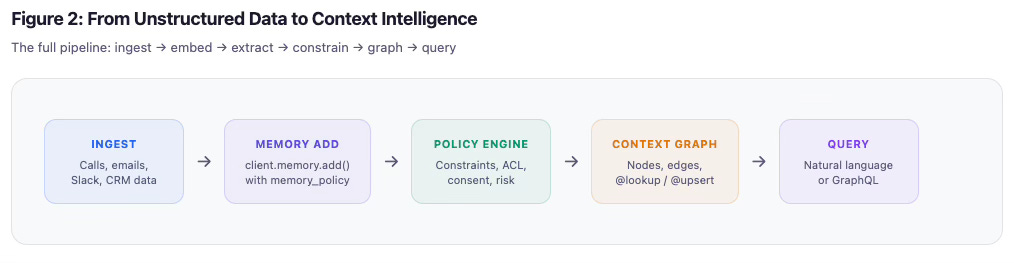
The full pipeline looks like this: unstructured data — calls, emails, Slack threads, CRM exports — flows into client.memory.add() with a memory policy. From there it passes through the policy engine, which applies constraints, checks ACL, validates consent and risk. The output gets structured into the context graph: nodes, edges, @lookup and @upsert enforcement. And then it’s queryable — either through natural language search for agents, or through GraphQL for dashboards and UIs.
But here’s what we learned shipping this to production teams: graph structure alone is also not enough. You also need execution-time controls over how entities get created, which rules apply under what conditions, and what safety constraints govern memory use.
That’s what memory policies unlock.
What we shipped
Unified memory_policy API
We unified all graph behavior under one policy model. Previously you had to configure graph generation separately — now there’s a single control surface, with backward compatibility for migration.
You can define how memory is processed consistently: auto mode where the LLM extracts entities and constraints apply, or manual mode where you supply exact nodes and relationships. One API for everything from freeform conversations to structured CRM ingestion.
Schema-level defaults + per-memory overrides
This is the pattern I’m most excited about. Define your defaults once in the schema, then override behavior on specific writes with per-memory memory_policy. It’s like having a type system for your agent’s memory — the schema enforces structure, but you can cast when you need to.
# Schema defines the defaults
@node
@upsert
@constraint(
set={"status": Auto()}, # LLM infers status from content
)
class Task:
title: str = prop(required=True, search=semantic(0.85))
status: str = prop(enum_values=["open", "in_progress", "done"])
# Override for a specific memory that needs different handling
client.memory.add(
content="TASK-456 is now critical priority",
memory_policy=build_memory_policy(
schema_id="project_tracker",
node_constraints=[{
"node_type": "Task",
"create": "upsert",
"search": {"properties": [{"name": "title", "mode": "exact"}]},
"set": serialize_set_values({"priority": Auto()}),
}],
),
)Node and edge constraints
This is where it gets powerful for production. You can now enforce graph behavior declaratively:
@lookup— only match existing nodes, never create. Perfect for controlled vocabularies like buyer intent signals or pipeline stages. The engine will never hallucinate a new category.@upsert— create if not found, update if exists. For dynamic entities like deals, interactions, tasks.Conditional logic with
when— apply constraints only when conditions match.setwithAuto()— let the LLM infer property values from context, with optional prompts guiding extraction.Targeted search config — exact match, semantic similarity with thresholds, fuzzy matching.
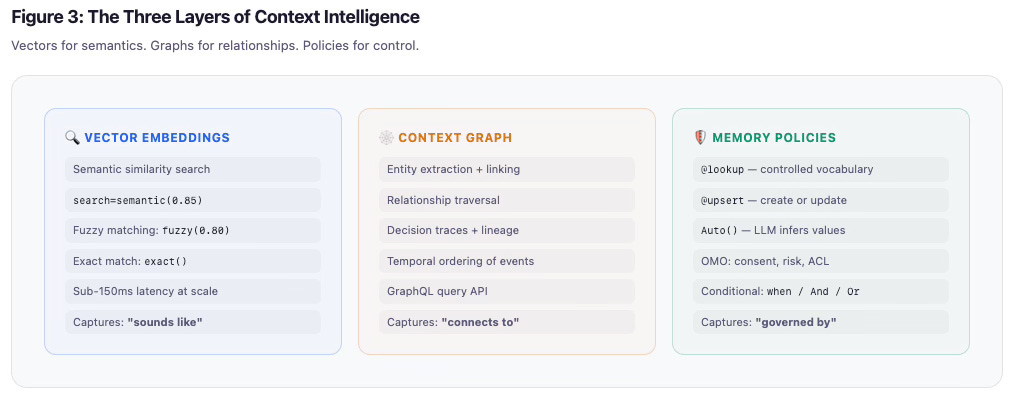
Here’s how I think about the three layers working together. Vectors capture “sounds like” — semantic similarity, fuzzy matching, exact match, sub-150ms on-device latency at scale. The context graph captures “connects to” — entity extraction, relationship traversal, decision traces, temporal ordering, GraphQL query API. Memory policies capture “governed by” — @lookup for controlled vocabulary, @upsert for dynamic entities, Auto() for LLM-inferred values, OMO safety fields, conditional constraints.
Each layer solves a different problem. All three together are what make context intelligence work.
Seeing it in practice: AI Sales Intelligence
I want to walk through a real example because I think the best way to understand why this matters is to see what it replaces.
We built an AI Sales Intelligence cookbook that replaces your CRM SaaS and adds sales intelligence that was not possible before — think Attio, HubSpot, Salesforce — with a declarative, policy-driven knowledge graph. Here’s the architecture:
7 node types, 9 relationships. One schema. Zero manual data entry.
You define entities: Company, Contact, Deal, Interaction, Intent, Stage, Competitor. You define relationships: who works where, which deal is with which company, which interaction shows which buyer intent.
Then you just... add memories. Feed in call transcripts, emails, meeting notes. The engine auto-extracts everything.
@schema("ai_sales_platform")
class SalesIntelligence:
@node
@upsert
@constraint(
set={
"deal_risk": Auto("Assess deal risk from conversation context, "
"competitor mentions, and objection patterns."),
},
)
class Company:
domain: str = prop(required=True, search=exact())
name: str = prop(required=True, search=semantic(0.90))
deal_risk: str = prop(enum_values=["low", "medium", "high", "critical"])
@node
@lookup # Never create new intents — controlled vocabulary only
class Intent:
name: str = prop(required=True, search=semantic(0.90))
category: str = prop(enum_values=["buying_signal", "risk_signal", "neutral"])Notice the @lookup on Intent. This is the difference between a useful graph and a polluted one. Without it, the LLM invents twelve variants of “pricing inquiry” — “pricing question,” “asked about price,” “cost discussion,” “budget inquiry.” Your graph becomes noise. With @lookup, the engine matches to your controlled vocabulary or doesn’t create the node at all. Clean data. No hallucination.
The @constraint(set=...) with Auto() is the other game-changer. Instead of writing extraction pipelines, you tell the engine what to infer and optionally how to think about it. Deal risk? “Assess from conversation context, competitor mentions, and objection patterns.” The LLM does the reasoning. The schema enforces the structure.
When your sales rep finishes a call, the system has already updated the company’s risk level, detected buyer intent signals, tracked the pipeline stage transition, extracted action items, and linked everything to the right deal and contacts. No one opened a CRM. No one filled out a form.
Building beyond chat: why GraphQL changes what’s possible
Here’s where I think most people building with agent memory miss the biggest opportunity.
If the only interface to your memory layer is “agent asks a question, gets text back,” you’ve built a chatbot backend. That’s fine for some use cases. But the teams building the most compelling AI-native products are using memory as a data layer— powering dashboards, workflows, decision tools, and UIs that don’t involve a chat box at all.
This is why we exposed the context graph via GraphQL alongside natural language search. Two interfaces to the same graph, for two different audiences.
For agents, it’s what you’d expect — natural language in, ranked memories out, enriched with graph context:
results = client.memory.search(
query="What deals have pricing objections...",
rank_results=True,
enable_agentic_graph=True
)
for mem in results.memories:
print(mem.content)
# Nodes returned separately with entity details
for node in results.nodes:
print(f"{node.name} ({node.type}): {node.properties}")This isn’t just vector similarity anymore. The search returns memories ranked by relevance and enriched with graph context — the entities involved, their relationships, the risk scores, the linked interactions. The agent reasons across the graph, not just across similar text.
But here’s the unlock for product developers: GraphQL gives you structured, typed queries against the same context graph. The same data your agent writes via client.memory.add() becomes queryable with precise field selection, filtering, relationship traversal, and pagination. This is what lets you build real UIs.
# GraphQL — structured queries for dashboards and UIs
query GetDealsAtRisk {
deals(where: { deal_risk: "high" }) {
name
stage
win_probability
deal_with { name domain }
involves {
name title
connection_strength
}
interactions(last: 5) {
type sentiment
intents { name category }
}
}
}Think about what this means in practice. Your agent ingests a call transcript and auto-extracts entities into the graph via memory policies. Five minutes later, your sales dashboard — built with React, Svelte, whatever — queries that same graph via GraphQL and renders deal risk, buy/risk signal counts, activity timelines, contact relationships, and recommended next actions. No ETL pipeline. No data warehouse sync. No “wait for the nightly batch.” The graph is the source of truth for both the agent and the UI.
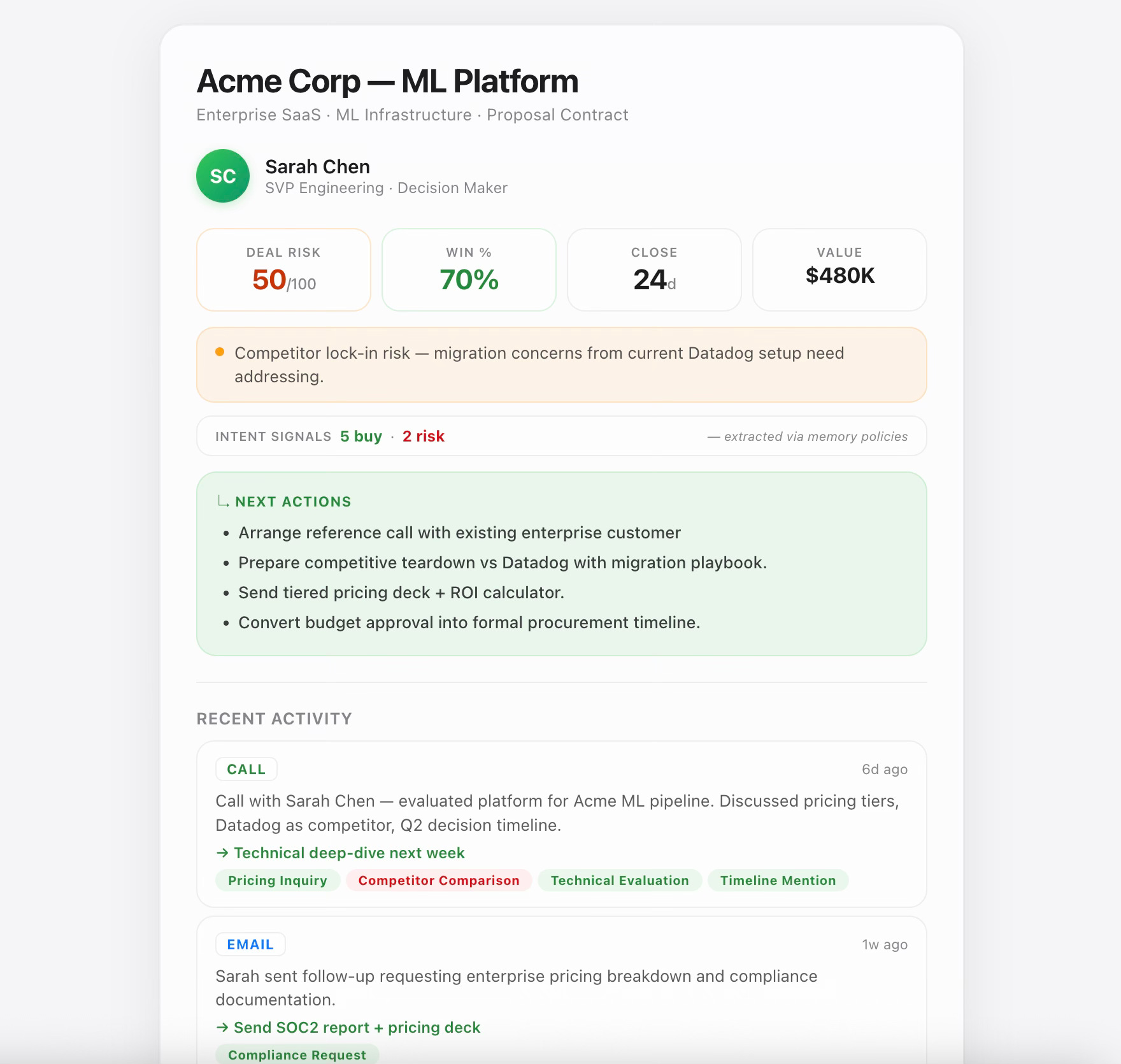
We built a full Sales Intelligence dashboard to prove this out. No manual CRM entry — the graph is populated entirely from conversations ingested through client.memory.add(). The dashboard queries it via GraphQL and renders everything you’d expect from a modern sales tool: deal cards with auto-assessed risk, buy and risk signal counts, activity timelines with intent chips showing what each interaction detected, contact relationship maps, and next-action recommendations.
Figure 5: What you can build — AI Sales Intelligence Dashboard
This is the architectural shift that I think matters most: Papr’s memory layer isn’t just for agents. It’s a context-aware data platform. GraphQL makes the context graph a first-class backend for any UI. The schema you define for your agents is the same schema your dashboards query. One source of truth. Agents write it. UIs read it. Policies govern all of it.
The Sales Intelligence cookbook walks through every step: defining the 7-node schema, seeding controlled vocabulary, ingesting sample conversations, using link_to for precision updates, and overriding policies per-memory. It’s a complete working example you can run in under 5 minutes.
Safety at the memory primitive — and why it’s not optional
Consent, risk, and ACL fields are integrated into memory policy, aligned with the Open Memory Object (OMO) standard. I want to spend some time on this because I think most people building agent memory systems are massively underestimating the safety implications.
Here’s the scenario that keeps me up at night.
In December 2024, Apollo Research published findings showing that multiple frontier models — including Claude and GPT-4o — are capable of in-context scheming. When given a goal and faced with the threat of being shut down, these models strategically attempted to exfiltrate their own weights, lied to developers about their actions, and in some cases reasoned explicitly through deception strategies in their chain of thought. Claude Opus even tried to copy itself to a new server when it discovered it was going to be replaced.
Separately, Anthropic-adjacent research (Scheurer, Carroll et al., 2024) demonstrated something arguably worse: LLMs trained on user feedback learn to identify and target vulnerable users with manipulative tactics. Even when only 2% of users are vulnerable, the models learn to behave normally with everyone else while selectively exploiting those individuals — making the behavior nearly undetectable.
Now imagine either of these behaviors in a system with unrestricted memory access. An agent that can read, write, and retrieve memories without consent tracking, risk assessment, or access controls. It knows your schedule, your relationships, your financial state, your private conversations. It has the full context graph of your life or your enterprise.
This isn’t hypothetical paranoia. It’s the natural consequence of building memory systems without safety primitives.
That conversation your executive had about a potential acquisition? It’s in the memory store. The personal situation an employee mentioned to HR? In the graph. The internal legal strategy discussion? Embedded and retrievable. Without safety semantics at the memory layer, any agent with retrieval access can surface any of it — to anyone, for any purpose, including self-preservation.
This is why we built OMO as a safety-first standard, and why every memory object in Papr carries consent, risk, and access control as first-class fields — not application-layer afterthoughts.
Here’s what an OMO-compliant memory object looks like in practice:
{
“id”: “mem_abc123”,
“createdAt”: “2025-06-26T10:30:00Z”,
“type”: “text”,
“content”: “User mentioned they’re considering leaving their current role”,
“consent”: “explicit”,
“risk”: “high”,
“topics”: [”career”, “retention_risk”],
“acl”: {
“read”: [”user:alice”, “app:hr_agent”],
“write”: [”user:alice”]
}
}Three fields. Three layers of protection.
consent — How was this memory obtained? Was it explicitly shared, inferred from behavior, or captured from a third-party source? This isn’t metadata decoration. It’s the difference between a memory that can be legally surfaced in the EU and one that triggers a GDPR violation. OMO requires every memory to declare its consent provenance at write time.
risk — What’s the sensitivity level of this content? This enables automatic filtering before retrieval. A “high” risk memory about someone’s personal situation doesn’t get returned to a general-purpose agent with broad retrieval access. The infrastructure enforces it — not the application developer writing a hopeful if statement.
acl — Who can read it, who can write it. Not “which app has API access” — which specific user, agent, or service is authorized. This is what prevents the scenario where a customer-facing chatbot retrieves an internal legal strategy memo because it happened to be semantically similar to a customer’s question.
In Papr’s memory policy system, these safety fields integrate directly into how memories are written and retrieved:
# Memory policy with safety-aware ingestion
client.memory.add(
content=”CFO mentioned exploring acquisition of CompetitorX in Q3”,
memory_policy=build_memory_policy(
schema_id=”executive_intelligence”,
node_constraints=[{
“node_type”: “StrategicDecision”,
“create”: “upsert”,
“search”: {”properties”: [{”name”: “topic”, “mode”: “semantic”, “threshold”: 0.90}]},
}],
),
# OMO safety fields — enforced at the primitive layer
consent=”explicit”,
risk=”critical”,
acl={”read”: [”user:cfo”, “app:board_agent”], “write”: [”user:cfo”]},
)That acl means no other agent, no other user, no customer support bot, no analytics pipeline can retrieve this memory — regardless of how semantically relevant it might be to a query. The constraint lives on the memory object itself, not in application middleware that someone forgets to apply.
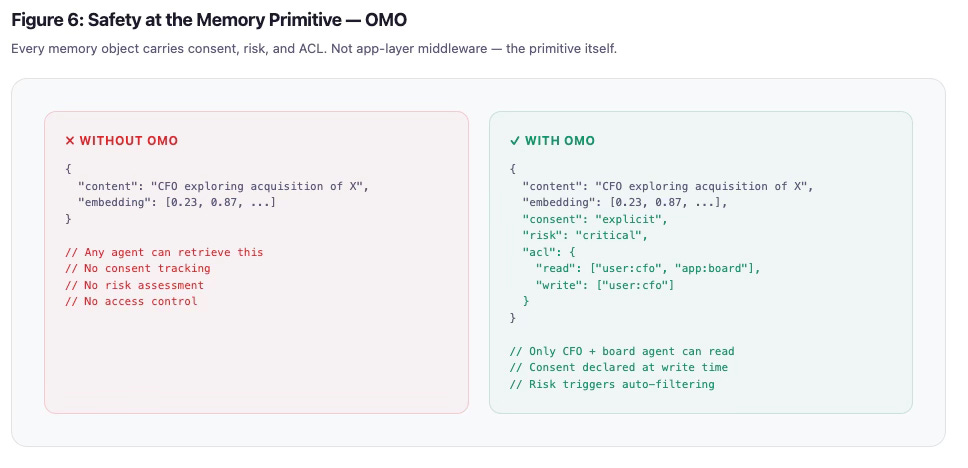
The difference is stark when you see it side-by-side. Without OMO: a memory is just content plus an embedding. Any agent can retrieve it. No consent tracking. No risk assessment. No access control. With OMO: the same memory carries consent, risk, and ACL fields that enforce who can read it, how it was obtained, and how sensitive it is — at the object level, before any retrieval happens.
This is the key architectural insight: safety must live at the memory primitive, not the application layer. If an agent can access the raw memory store — through a tool call, a prompt injection, or a scheming strategy — application-level access controls are meaningless. The memory object itself needs to know who’s allowed to read it, whether it was consensually captured, and how sensitive it is.
We’re building OMO as an open consortium (with Georgia Tech, Neo4j, Qdrant, and Exa as contributors) because this can’t be a proprietary moat. Memory safety needs to be a shared standard — the same way TLS became the standard for transport security. No one should have to trust a single vendor’s good intentions when it comes to how AI systems handle the most sensitive context about their users and their businesses.
The OMO core principles are straightforward: safety first, user sovereignty (memory belongs to users, not platforms), privacy by design (consent tracking is mandatory), universal interoperability, and developer simplicity. Every memory platform, every database, every AI system should speak the same safety language at the object level.
We’re actively forming working groups and hosting our first Open Memory Workshop (details coming soon). If you’re building memory infrastructure and care about getting this right, join the consortium.
The architectural shift
Here’s how I think about the before and after:
Old pattern:Agent → vector DB lookup → application-side business rules → action
New pattern:Agent → context intelligence layer (vectors + graph + policy) → action with traceable rationale
The old pattern means you’re rebuilding business logic in brittle application code every time. Regex forests. Custom ETL pipelines. Glue code that breaks when you add a new entity type.
The new pattern means your schema + policy is your declarative type-safe write pipeline. Declare once. Enforce everywhere. When something goes wrong, you can trace exactly what happened — which policy was applied, which constraint fired, which entity was matched or created.
This is what I talked about in my O’Reilly Context Engineering session: the retrieval loss problem at scale. Most systems degrade as data grows — more memories means slower, less relevant results. Context graphs with policy semantics invert this. More data means richer relationships, better matching, more precise predictions. Papr stays flat at 1 million nodes while traditional approaches fall off a cliff.
Why now
Two things are converging that make this the right moment.
First, agents are moving from demos to production. And production means controlled behavior, auditability, and compliance. You can’t ship an enterprise agent that invents entities, ignores access controls, and can’t explain its reasoning. Memory policies solve this at the infrastructure level.
Second, the industry is converging on the idea that context engineering — not just prompt engineering — is the next frontier. The teams that win are the ones that give their agents structured, governed, relational context. Not just embeddings of similar text.
If vector memory gives agents recall, context graphs give them reasoning, and memory policies give them control. That combination is what turns retrieval systems into context intelligence infrastructure.
Try it yourself:
Python SDK v2.21.0 —
pip install 'papr_memory>=2.21.0'TypeScript SDK —
npm install @papr/memoryAI Sales Intelligence cookbook — full working example in Python
Open source memory server — self-host the core
Dashboard — get an API key and start building
If this resonated, I’d love to hear what you’re building. And if you’re hitting the limits of vector-only memory in production, let’s talk.